Blog
Optimization: Simplicity vs Speed, Part 1- Regular Expression vs Character Operations
![]()
Knowing when to simplify or diversify code, when to use pre-built methods or create our own and what approach to take as a developer, is crucial to efficiency. Here at Beringer, our developers are dedicated to studying optimization for the utmost benefit of our clients. What follows is an examination into four different methods; Regular Expression (RegEx), character operations (Char-Ops), Quick Sort and Heap Sort that we recently performed.
The goal was to determine which method was simpler and which guaranteed faster performance. The results confirm what appears simplest and quickest is often not the case in code. Read on below to learn more about the differences between RegEx and Char Ops.
The application tested below is an implementation of the mathematical Collatz Conjecture. Simply stated, the conjecture claims that any positive number can reach 1 by one of two ways. If even, divide by 2. If odd, multiply by 3 and add 1. The application written here tests this conjecture using the methods mentioned above. Each number reached on the path to 1 is stored in an array and sorted. The largest number in the array is produced. The end of the application also provides a comparison in milliseconds of the run time between the different methods. The important operations in this application were looped 10,000 times to test optimization.
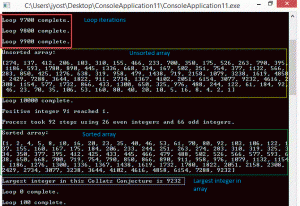
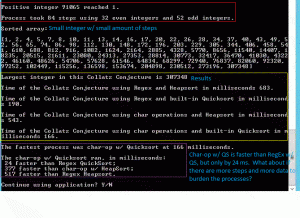
The optimization test above show the iterations and arrays. The second test demonstrates that Char-Ops is faster than RegEx, but only by a small margin. Both Char-Ops and RegEx serve to remove punctuation and other non-numeric characters from user input. The numbers used were “91” and “91065,” neither of which have punctuation So what happens if we increase the overhead with punctuation?
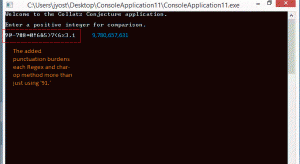
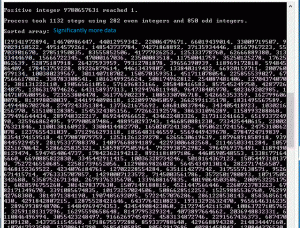
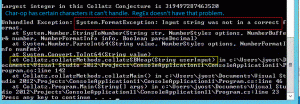
The entry above is actually “9,780,657,631.” It is the largest recorded positive integer below 100 billion with the most steps to 1. This number requires 1,132 steps.
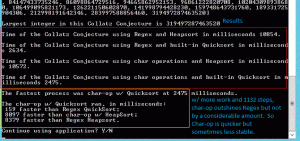 The image to the left demonstrates again that Char-Ops is faster than RegEx. It’s safe to assume that larger inputs increase the gap between Char-Ops and RegEx. But is it worth it? The image above shows an error thrown by Char-Ops. Unlike RegEx, Char-Ops was unable to handle the ‘$’ sign. So is RegEx the better option for optimization? Let’s have a look.
The image to the left demonstrates again that Char-Ops is faster than RegEx. It’s safe to assume that larger inputs increase the gap between Char-Ops and RegEx. But is it worth it? The image above shows an error thrown by Char-Ops. Unlike RegEx, Char-Ops was unable to handle the ‘$’ sign. So is RegEx the better option for optimization? Let’s have a look.
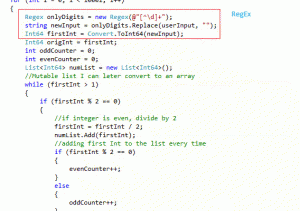
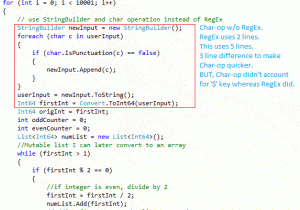
Char-Ops (second) takes a few more lines of code whereas RegEx(first) takes less. RegEx appears simpler and easier to implement, but the code is deceptive. After RegEx we see @”[^d]+” which tells RegEx to only take numbers. If this looks like nonsense to you, you aren’t alone. We could also write that as ^[a-zA-Z0-9_]*$” so now RegEx more complex.
Though Char-Ops is verbose, it is simple and clear. Char.IsPunctuation( c ) asks if the character is a punctuation and then acts accordingly. Though ‘$’ was problematic, another line or two of code could mitigate this. More advanced users of RegEx can also tell us that RegEx can have severe impact on computer memory. Ultimately, it is not as cut and dry as one method being faster than another. Detailed analysis and understanding of optimization is vital to the success of any software developer.
Here at Beringer Associates, we strongly agree with this work ethic. Feel free contact us at Beringer and watch for the part 2 blog for an examination of Quick Sort and Heap Sort.
Recent Posts





How can we help?
Whether you're seeking a fully managed IT solution or expert assistance with a Microsoft solution, we're here to provide expert advice whenever you need it.
Call us at (800) 796-4854 or complete the form below and we'll help in any way we can.