Blog

Scaling Data Load with Azure
Fine tuning an integration to optimize speed is more of an art than a science, especially when you are looking for the sweet spot of diminishing returns. One of the biggest challenges when migrating large data sets is optimizing the integration to run as fast as possible, without running into resource limitations.
There are a few factors at play:
- What compute resources do I have available?
- Is my integration developed to scale based on the available resources?
- How many connections can I create both at the source and destination, without overwhelming the endpoints?
- Do I have enough bandwidth available?
I’m excited to see the latest version of Microsoft Azure Data Factory now supports automatic scaling with on demand processing power. Azure Data Factory is a cloud-based data integration service that orchestrates and automates the movement and transformation of data. You can create data integration solutions using the Data Factory service that can ingest data from various data stores, transform/process the data, and publish the result data to the data stores. The latest release of Azure Data Factory (Version 2) builds upon the Data Factory version 1, and supports a broader set of cloud-first data integration scenarios. You can check out all of the new features here.
Azure Data Factory Test 1
I decided to put Azure Data Factory to the test, and see how quick I could push around 10,000 records. For my first test, I’m using an on premise SQL server as my source, and Dynamics 365 as my destination. Both are sandbox systems, and not particularly powerful. I left both the Data Integration Unit and Degree of Copy Parallelism set to Auto, which will allow Azure Data Factory to automatically scale. My results show that Azure Data Factory scaled to a maximum of 10 parallel copies, and pushed the data at an average rate of 100 records per second.
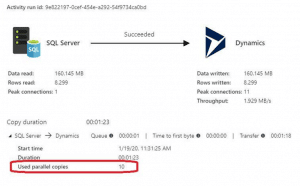
Azure Data Factory Test 2
For my second test, I maxed out the Data Integration Unit and Degree of Copy Parallelism to 32, which forced Azure Data Factory to scale to its limits. The results increased 33% to an average rate of 132 records per second. While I’m happy with the speed increase, this test cost me more money than the first. I’m sure I would see even faster results if I had a beefier SQL server, or production ready Dynamics API’s available.
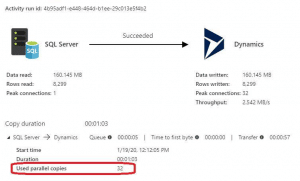
Azure Data Factory Test 3
For my final test, I dropped the Data Integration Unit and Degree of Copy Parallelism to 2, which is the minimum threshold for Azure Data Factory. My results dove to an average rate of 39 records per second. While the speed certainly dropped off, so did the cost. If speed is not a issue, then this approach is the most cost effective.
“The best part of my Azure integration is that I only paid for the duration of the actual resource utilization”
I’ve worked with other data migration solutions in the past, but I was never able to reach this type of speed without manually segregating the integration for scale, and procuring a very expensive machine to execute it. With Azure Data Factory, the integration runtime provides a fully managed, serverless compute in Azure. It’s refreshing to not worry about infrastructure provision, software installation, patching, or capacity scaling.
Reach out to Beringer today!
We love to implement cloud applications and integrate data here at Beringer Technology Group. We have a tremendous amount of experience working with iPaaS solutions, and we’re always finding innovative ways to help smooth the transition to the cloud. I hope that you have your head in the clouds, and are embracing cloud technology.
Recent Posts





How can we help?
Whether you're seeking a fully managed IT solution or expert assistance with a Microsoft solution, we're here to provide expert advice whenever you need it.
Call us at (800) 796-4854 or complete the form below and we'll help in any way we can.